Business & Economics
IT Revolution
October 15, 2014
348

I am a certified Scrum Master. I have run Agile Development efforts in a software engineering group. In my past, I have been involved and lead Quality Process implementations – ISO 9001, New York State Governor’s Award, COPC (call center standards), etc. DevOps appeals to me because I am quality process kind of guy. I might have to get myself another certification. 🙂
The only thing more dangerous than a developer is a developer conspiring with Security. The two working together gives us means, motive, and opportunity.
I’ve seen this movie before. The plot is simple: First, you take an urgent date-driven project, where the shipment date cannot be delayed because of external commitments made to Wall Street or customers. Then you add a bunch of developers who use up all the time in the schedule, leaving no time for testing or operations deployment. And because no one is willing to slip the deployment date, everyone after Development has to take outrageous and unacceptable shortcuts to hit the date. The results are never pretty. Usually, the software product is so unstable and unusable that even the people who were screaming for it end up saying that it’s not worth shipping. And it’s always IT Operations who still has to stay up all night, rebooting servers hourly to compensate for crappy code, doing whatever heroics are required to hide from the rest of the world just how bad things really are.
We brought in some consultants, who helped us replace our ticketing system with an ITIL-compliant change management tool. People
ITIL stands for IT Infrastructure Library, which documents many IT best practices and processes, and the ITIL program has had a reputation of spending years merely walking in circles.
respond, “You said that people ‘add stuff to our list.’ What does the list look like right now? Where can I get a copy? Who owns the list?” Wes replies slowly, “Well, there are the business projects and the various IT infrastructure projects. But a lot of the commitments just aren’t written down.” “How many business projects? How many infrastructure projects?” I ask. Wes shakes his head. “I don’t know offhand. I can get the list of business projects from Kirsten, but I’m not sure if anyone knows the answer to your second question. Those don’t go through the Project Management Office.”
How can we manage production if we don’t know what the demand, priorities, status of work in process, and resource availability are?
We can’t make new commitments to other people when we don’t even know what our commitments are now!” I say. “At the very least, get me the work estimate to fix the audit findings. Then, for each of those resources, tell me what their other commitments are that we’re going to be pulling them off of.”
“I merely want a one-line description about what all that work is and how long they think it will take!”
We bump up the priorities of things all the time, but we never really know what just got bumped down. That is, until someone screams at us, demanding to know why we haven’t delivered something.”
“The third largest item is incident and break-fix work. Right now, it’s probably consuming seventy-five percent of our staff’s time. And because these often involve critical business systems, incidents will take priority over everything else, including Phoenix and fixing audit findings.
The one consistent theme in the interviews was that everyone struggles to get their project work done. Even when they do have time, they struggle to prioritize all their commitments. People in the business constantly ask our staff to do things for them. Especially Marketing.”
‘change’ is any activity that is physical, logical, or virtual to applications, databases, operating systems, networks, or hardware that could impact services being delivered.”
“How about I write up the outputs of the meeting and the new instructions for submitting requests for changes?”
“You probably don’t even see when work is committed to your organization. And if you can’t see it, you can’t manage it—let alone organize it, sequence it, and have any assurance that your resources can complete it.”
“In the 1980s, this plant was the beneficiary of three incredible scientifically-grounded management movements. You’ve probably heard of them: the Theory of Constraints, Lean production or the Toyota Production System, and Total Quality Management.
WIP is the silent killer. Therefore, one of the most critical mechanisms in the management of any plant is job and materials release. Without it, you can’t control WIP.”
“Because of how Mark was releasing work, inventory kept piling up in front of our bottleneck, and jobs were never finished on time. Every day was an emergency. For years, we were awarded Best Customer of the Year from our air freight shipment company, because we were overnighting thousands of pounds of finished goods to angry customers almost every week.”
“Eliyahu M. Goldratt, who created the Theory of Constraints, showed us how any improvements made anywhere besides the bottleneck are an illusion.
Any improvement made after the bottleneck is useless, because it will always remain starved, waiting for work from the bottleneck. And any improvements made before the bottleneck merely results in more inventory piling up at the bottleneck.”
“Your job as VP of IT Operations is to ensure the fast, predictable, and uninterrupted flow of planned work that delivers value to the business while minimizing the impact and disruption of unplanned work, so you can provide stable, predictable, and secure IT service.”
You must figure out how to control the release of work into IT Operations and, more importantly, ensure that your most constrained resources are doing only the work that serves the goal of the entire system, not just one silo.
“The First Way helps us understand how to create fast flow of work as it moves from Development into IT Operations, because that’s what’s between the business and the customer. The Second Way shows us how to shorten and amplify feedback loops, so we can fix quality at the source and avoid rework. And the Third Way shows us how to create a culture that simultaneously fosters experimentation, learning from failure, and understanding that repetition and practice are the prerequisites to mastery.”
“Excellent! The first ones are the low-risk changes that ITIL calls ‘standard changes.’ For changes we’ve done many times before successfully, we just preapprove. They still need to be submitted, but they can be scheduled without us.”
For the ‘messy middle changes,’ we’re deciding that the change submitter has responsibility and accountability for consulting and getting approval from people potentially affected. Once they do that, they submit their change card for us to review and approve for scheduling.”
“How many changes are scheduled for Friday?” Bingo. Patty flashes a small smile and says, “173.” On the board, it’s now very obvious that nearly half the changes were scheduled for Friday. Of the remaining, half are scheduled for Thursday with the rest sprinkled earlier in the week.
I’m worried about change collisions and resource-availability conflicts. Friday is also the day Phoenix is being deployed. “If I were air traffic control,” she continues, “I’d say that the airspace is dangerously overcrowded. Anyone willing to change their flight plans?”
Bill mentioned the four types of work: business projects, IT Operations projects, changes, and unplanned work. Left unchecked, technical debt will ensure that the only work that gets done is unplanned work!”
Unplanned work has another side effect. When you spend all your time firefighting, there’s little time or energy left for planning. When all you do is react, there’s not enough time to do the hard mental work of figuring out whether you can accept new work. So, more projects are crammed onto the plate, with fewer cycles available to each one, which means more bad multitasking, more escalations from poor code, which mean more shortcuts. As Bill said, ‘around and around we go.’ It’s the IT capacity death spiral.”
“Are we even allowed to say no? Every time I’ve asked you to prioritize or defer work on a project, you’ve bitten my head off. When everyone is conditioned to believe that no isn’t an acceptable answer, we all just became compliant order takers, blindly marching down a doomed path. I wonder if this is what happened to my predecessors, too.”
Because you have no idea what capacity you actually have. You’re like the guy who is always writing checks that bounce, because you don’t know how much money you have and never bother opening your mail.
The business would make absurd commitments to ship something at some impossible date, oblivious to all the work already in the system.”
What got worked on was based on who yelled the loudest or most often, who could engineer the best side deals with the expediters, or who could get the ear of the highest ranking executive.”
the goal is to increase the throughput of the entire system, not just increase the number of tasks being done.
“You’ve been a plant manager. Think of it as freezing materials release until enough WIP completes and leaves the plant. In order to control this system, we need to reduce the number of moving parts.”
“I’ll tell you about wasteful. How about over a thousand changes stuck in the system, with no apparent way of ever getting them completed?” Wes frowns. Then he nods, saying, “That’s true. The number of cards on Patty’s change board keeps going up. If that’s work in process, it’s definitely spiraling out of control. We’re probably only a couple weeks away from having those cards stacked to the ceiling, too.”
Operations will freeze all non-Phoenix work. Development can’t idle the twenty-plus non-Phoenix projects, but will freeze all deployments. In other words, no work will flow from Development to IT Operations for another two weeks.
we will identify the top areas of technical debt, which Development will tackle to decrease the unplanned work being created by problematic applications in production.
The outage will impact our quarterly revenue, but we don’t know how much yet. In order to prevent this from happening again, we’re putting together a project to monitor our critical systems for unauthorized changes.
“When we have multiple streams of work going on simultaneously, how does anyone decide what needs to get worked on at any given time?”
“Priority 1 is whoever is yelling the loudest, with the tie-breaker being who can escalate to the most senior executive. Except when they’re more subtle. I’ve seen a bunch of my staff always prioritizing a certain manager’s requests, because he takes them out to lunch once a month.”
“If this is true, there’s no way we can lift the project freeze. Don’t you see that we don’t have any way of releasing work into IT and be able to trust that it will get worked on?”
WIP goes from work center to work center, as dictated by the bill of materials and routings. And all that is in the job order, which was released at that desk over there.”
“Good. Understanding the flow of work is key to achieving the First Way,”
“The heat treat oven is a work center, which has workers associated with it. You asked what work centers are our constraints, and I told you that it was Brent, which can’t be right, because Brent isn’t a work center. “Brent is a worker, not a work center,” I say again. “And I’m betting that Brent is probably a worker supporting way too many work centers. Which is why he’s a constraint.”
“every work center is made up of four things: the machine, the man, the method, and the measures. Suppose for the machine, we select the heat treat oven. The men are the two people required to execute the predefined steps, and we obviously will need measures based on the outcomes of executing the steps in the method.”
“Work center: machine, man, method, measure.”
“You’re standardizing Brent’s work so that other people can execute it. And because you’re finally getting those steps documented, you’re able to enforce some level of consistency and quality, as well. You’re not only reducing the number of work centers where Brent is required, you’re generating documentation that will enable you to automate some of them.”
“Incidentally, until you do this, no matter how many more Brents you hire, Brent will always remain your constraint. Anyone you hire will just end up standing around.”
“What you’re building is the bill of materials for all the work that you do in IT Operations. But instead of a list of parts and subassemblies, like moldings, screws, and casters, you’re cataloging all the prerequisites of what you need before you can complete the work—like laptop model numbers, specifications of user information, the software and licenses needed, their configurations, version information, the security and capacity and continuity requirements, yada yada…”
you’re actually building a bill of resources. That’s the bill of materials along with the list of the required work centers and the routing. Once you have that, along with the work orders and your resources, you’ll finally be able to get a handle on what your capacity and demand is. This is what will enable you to finally know whether you can accept new work and then actually be able to schedule the work.”
“Properly elevating preventive work is at the heart of programs like Total Productive Maintenance, which has been embraced by the Lean Community. TPM insists that we do whatever it takes to assure machine availability by elevating maintenance. As one of my senseis would say, ‘Improving daily work is even more important than doing daily work.’ The Third Way is all about ensuring that we’re continually putting tension into the system, so that we’re continually reinforcing habits and improving something. Resilience engineering tells us that we should routinely inject faults into the system, doing them frequently, to make them less painful. “Mike Rother says that it almost doesn’t matter what you improve, as long as you’re improving something. Why? Because if you are not improving, entropy guarantees that you are actually getting worse, which ensures that there is no path to zero errors, zero work-related accidents, and zero loss.”
“Rother calls this the Improvement Kata,” he continues. “He used the word kata, because he understood that repetition creates habits, and habits are what enable mastery. Whether you’re talking about sports training, learning a musical instrument, or training in the Special Forces, nothing is more to mastery than practice and drills. Studies have shown that practicing five minutes daily is better than practicing once a week for three hours. And if you want to create a genuine culture of improvement, you must create those habits.”
“Before we leave, turn your attention from the work centers to all the space between the work centers. Just as important as throttling the release of work is managing the handoffs. The wait time for a given resource is the percentage that resource is busy, divided by the percentage that resource is idle. So, if a resource is fifty percent utilized, the wait time is 50/50, or 1 unit. If the resource is ninety percent utilized, the wait time is 90/10, or nine times longer. And if the resource is ninety-nine percent utilized?” Although I’m not quite understanding the relevance, I do the math in my head: 99/1. I say, “Ninety-nine.”
“When a resource is ninety-nine percent utilized, you have to wait ninety-nine times as long as if that resource is fifty percent utilized.”
critical part of the Second Way is making wait times visible, so you know when your work spends days sitting in someone’s queue—or worse, when work has to go backward, because it doesn’t have all the parts or requires rework. “Remember that our goal is to maximize flow.
This should be your guiding principle: You win when you protect the organization without putting meaningless work into the IT system. And you win even more when you can take meaningless work out of the IT system.”
The biggest risk to Parts Unlimited is going out of business.
“Jimmy, Parts Unlimited has at least four of my family’s credit card numbers in your systems. I need you to protect that data. But you’ll never adequately protect it when the work product is already in production. You need to protect it in the processes that create the work product.”
“You want a clue? Go to MRP-8 plant and find the plant safety officer. Go talk to her, find out what she’s trying to accomplish and how she does it.”
“We know that IT work can be projects or changes. And in many of the projects, there are many tasks or subprojects that show up over and over again. Like setting up a server. It’s recurring work. I guess you could call that a subassembly.”
“Let’s use the example of configuring a server. It involves procurement, installing the OS and applications on it according to some specification, and then getting it racked and stacked. Then we validate that it’s been built correctly. Each of these steps are typically done by different people. Maybe each step is like a work center, each with its own machines, methods, men, and measures.”
“Maybe the machine,” I speculate, “is the tools necessary to do the work? The virtualization management consoles, terminal sessions, and maybe the virtual disk space that we attach to it?” Patty shakes her head. “Maybe. The consoles and terminals sound like they could be the machine. And I think disk space, the applications, license keys, and so forth are all actually inputs or the raw materials needed to create the outputs.”
a kanban board, among many other things, is one of the primary ways our manufacturing plants schedule and pull work through the system. It makes demand and WIP visible, and is used to signal upstream and downstream stations.
Any activities they work on must go through the kanban. Not by e-mail, instant message, telephone, or whatever. “If it’s not on the kanban board, it won’t get done,” she says. “And more importantly, if it is on the kanban board, it will get done quickly. You’d be amazed at how fast work is getting completed, because we’re limiting the work in process. Based on our experiments so far, I think we’re going to be able to predict lead times for work and get faster throughput than ever.”
Improvement Kata they’ve adopted. Believe it or not, Erik helped them institute it many years ago. They have continual two-week improvement cycles, each requiring them to implement one small Plan-Do-Check-Act project to keep them marching toward the goal. You
Note:pdca!
Once we figure out what our most frequently recurring tasks are, we need to create work centers and lanes of work, just like I did for my service requests. Maybe we can even get rid of some of this scheduling, and create kanban boards instead.
So, the purple cards are the changes supporting one of the top five business projects, otherwise, they’re yellow. The green cards are for internal IT improvement projects, and we’re experimenting with allocating twenty percent of our cycles just for those, as Erik recommended we do. At a glance, we can confirm that there’s the right balance of purple and green cards in work.”
“The pink sticky notes indicate the cards that are blocked somehow, which we’re therefore reviewing twice a day. We’re also putting all these cards back into our change tracking tool, so we’re putting the change IDs on each of the cards, too.
projects seem to fall into the following categories: replacing fragile infrastructure, vendor upgrades, or supporting some internal business requirement. The rest are a hodgepodge of audit and security work, data center upgrade work, and so forth.”
“I don’t care how important everyone thinks their project is. We need to know whether it increases our capacity at our constraint, which is still Brent. Unless the project reduces his workload or enables someone else to take it over, maybe we shouldn’t even be doing it. On the other hand, if a project doesn’t even require Brent, there’s no reason we shouldn’t just do it.”
We need to keep Brent’s capacity up by reducing the amount of unplanned work that hits him.”
“We’re doing what Manufacturing Production Control Departments do. They’re the people that schedule and oversee all of production to ensure they can meet customer demand. When they accept an order, they confirm there’s enough capacity and necessary inputs at each required work center, expediting work when necessary. They work with the sales manager and plant manager to build a production schedule so they can deliver on all their commitments.”
“managing the IT Operations production schedule” should be somewhere in my job description.
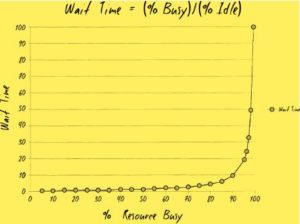
I tell them what Erik told me at MRP-8, about how wait times depend upon resource utilization. “The wait time is the ‘percentage of time busy’ divided by the ‘percentage of time idle.’ In other words, if a resource is fifty percent busy, then it’s fifty percent idle. The wait time is fifty percent divided by fifty percent, so one unit of time. Let’s call it one hour. So, on average, our task would wait in the queue for one hour before it gets worked. “On the other hand, if a resource is ninety percent busy, the wait time is ‘ninety percent divided by ten percent’, or nine hours. In other words, our task would wait in queue nine times longer than if the resource were fifty percent idle.” I conclude, “So, for the Phoenix task, assuming we have seven handoffs, and that each of those resources is busy ninety percent of the time, the tasks would spend in queue a total of nine hours times the seven steps…”
Those projects certainly represent two categories of work: business projects and internal IT projects.
this week. I realize that changes are the third category of work.
But what is the relationship between changes and projects? Are they equally important?
changes are a type of work different than projects, does that mean that we’re actually doing more than just the hundred projects? How many of these changes are to support one of the hundred projects? If it’s not supporting one of those, should we really be working on it?
Every time that we let Brent fix something that none of us can replicate, Brent gets a little smarter, and the entire system gets dumber. We’ve got to put an end to that.
want a timesheet from Brent every day, and I want every escalation Brent works in the ticketing system. We need that documented so we can analyze it later. Anyone using Brent’s time will need to justify it to me. If it’s not justified, I’ll escalate it to Steve, and that person and his manager will have to explain
Erik called WIP, or work in process, the “silent killer,” and that inability to control WIP on the plant floor was one of the root causes for chronic due-date problems and quality issues.
“Patty, we need a better understanding of what work is going to be heading Brent’s way. We need to know which change cards involve Brent—maybe we even make that another piece of information required when people submit their cards. Or use a different color card—you figure it out. You need to inventory what changes need anything from Brent, and try to satisfy it instead with the level 3 engineers. Failing that, try to get them prioritized so we can
I smirk at the reference to smoke tests, a term circuit designers use. The saying goes, “If you turn the circuit board on and no smoke comes out, it’ll probably work.”
we’ve gotten so sloppy about keeping track of version numbers of the entire release. Each time they fix something, they’re usually breaking something else. So, they’re sending single files over instead of the entire package.”
want a single entry point for code drops, controlled hourly releases, documentation… Get
We made a huge investment in virtualization, which was supposed to save us from things like this. But, when Development couldn’t fix the performance problems, they blamed the virtualization. So we had to move everything back onto physical servers!” And to think that Chris proposed this aggressive rollout date because virtualization would save our asses.
“I need the business to tell me it’s no longer being held hostage by you IT guys. This has been the running complaint the entire time I’ve been CEO. IT is in the way of every major initiative. Meanwhile, our competitors pull away from us, leaving us in the dust. Dammit, we can’t even take a crap without IT being in the way.”
My engineers keep getting pulled off of feature development to handle escalations when things break. And deployments keep taking longer and longer. What used to take ten minutes to deploy starts taking an hour. Then a full day, then an entire weekend, then four days. I’ve even got some deployments that are now taking over a week to complete. Like Phoenix.”
We can’t even plan effectively for one year, let alone three years! What’s the use?”
A fellow NCO in the Marines once told me that his priorities were the following: provider, parent, spouse, and change agent. In that order.
had called Erik briefly to tell him that I had discovered three of the four categories of work: business projects, internal projects, and changes. He merely said that there was one more type of work, maybe the most important type, because it’s so destructive. And in a searing moment of insight, I think I know what the fourth category of
Maybe what I’m looking for is like dark matter. You can only see it by what it displaces or how it interacts with other matter that we can see. Patty called it firefighting. That’s work, too, I suppose. It certainly kept everyone up at all hours of the night. And it displaced all the planned changes.
All the firefighting displaced all the planned work, both projects and changes.
What can displace planned work? Unplanned work.
Unplanned work is what prevents you from doing it. Like matter and antimatter, in the presence of unplanned work, all planned work ignites with incandescent fury, incinerating everything around it.
The fourth category of work is unplanned work!”
unplanned work is recovery work, which almost always takes you away from your goals. That’s why it’s so important to know where your unplanned work is coming from.”
“You’ve put together tools to help with the visual management of work and pulling work through the system. This is a critical part of the First Way, which is creating fast flow of work through Development and IT Operations. Index cards on a kanban board is one of the best mechanisms to do this, because everyone can see WIP. Now you must continually eradicate your largest sources of unplanned work, per the Second Way.”
You’ve started to take steps to stabilize the operational environment, you’ve started to visually manage WIP within IT Operations, and you’ve started to protect your constraint, Brent. You’ve also reinforced a culture of operational rigor and discipline. Well done, Bill.”
you definitely need to know about constraints because you need…
hope as part of your curriculum, you read The Goal by Dr. Eli Goldratt. If you don’t have a copy anymore, get another…
“Goldratt taught us that in most plants, there are a very small number of resources, whether it’s men, machines, or materials, that dictates the output of the entire system. We call this the constraint—or bottleneck. Either term works. Whatever you call it, until you create a trusted system to manage the flow of work to the constraint, the constraint is constantly wasted, which means that the constraint is likely being drastically underutilized.
“That means you’re not delivering to the business the full capacity available to you. It also likely means that you’re not paying down technical debt, so your problems and amount of unplanned work continues to increase over time,” he says.
“There are five focusing steps which Goldratt describes in The Goal: Step 1 is to identify the constraint. You’ve done that, so congratulations. Keep challenging yourself to really make sure that’s your organizational constraint, because if you’re wrong, nothing you do will matter. Remember, any improvement not made at the constraint is just an illusion, yes? “Step 2 is to exploit the constraint,” he continues. “In other words, make sure that the constraint is not allowed to waste any time. Ever. It should never be waiting on any other resource for anything, and it should always be working on the highest priority commitment the IT Operations organization has made to the rest of the enterprise. Always.”
unplanned work kills your ability to do planned work, so you must always do whatever it takes to eradicate it. Murphy does exist, so you’ll always have unplanned work, but it must be handled efficiently.
“But you’re ready to start thinking about Step 3, which is to subordinate the constraint. In the Theory of Constraints, this is typically implemented by something called Drum-Buffer-Rope. In The Goal, the main character, Alex, learns about this when he discovers that Herbie, the slowest Boy Scout in the troop, actually dictates the entire group’s marching pace. Alex moved Herbie to the front of the line to prevent kids from going on too far ahead. Later at Alex’s plant, he started to release all work in accordance to the rate it could be consumed by the heat treat ovens, which was his plant’s bottleneck. That was his real-life Herbie.” “Fully two decades after The Goal was published,” he continues, “David J. Anderson developed techniques of using a kanban board to release work and control WIP for Development and IT Operations. You may find that of interest. You and Penelope are close with your change board to a kanban board that can manage flow.” “So, here’s your homework,” he says. “Figure out how to set the tempo of work according to Brent. Once you make the appropriate mapping of IT Operations to work on the plant floor, it will be obvious.
“Figure out how to set the tempo of work according to Brent. Once you make the appropriate mapping of IT Operations to work on the plant floor, it will be obvious.
Chester, your peer in Development, is spending all his cycles on features, instead of stability, security, scalability, manageability, operability, continuity, and all those other beautiful ’itties.
You need to design these things, what some call ‘nonfunctional requirements,’ into the product. But your problem is that the person who knows the most about where your technical debt is and how to actually build code that is designed for Operations is too busy.
there’s still a big piece of the First Way that you’re missing. Jimmy’s problem with the auditors shows that he can’t distinguish what work matters to the business versus what doesn’t. And incidentally, you have the same problem, too. Remember, it goes beyond reducing WIP. Being able to take needless work out of the system is more important than being able to put more work into the system.
you need to know what matters to the achievement of the business objectives, whether it’s projects, operations, strategy, compliance with laws and regulations, security, or whatever.”
“Remember, outcomes are what matter—not the process, not controls, or, for that matter, what work you complete.”
Afterward, we did the first of a series of ongoing blameless postmortems to figure out what really happened and come up with ideas on how to prevent it from happening again. Better yet, Patty led a series of mock incident calls with all hands on deck, to rehearse the new procedures.
I know that my most rewarding times were always when I was part of a great team. That goes for both my professional and personal life.
What made those teams great is that everyone trusted one another. It can be a powerful thing when that magic dynamic exists.
“One of my favorite books about team dynamics is Five Dysfunctions of a Team, by Patrick Lencioni. He writes that in order to have mutual trust, you need to be vulnerable.
I have to fulfill my obligations to the US Army, which is where I discover my love for logistics. I make sure materials get to where they need to.
is not just a department. IT is a competency that we need to gain as an entire company.
“Which makes me think,” he says, looking around the room, “that we’re probably not good at making internal commitments to one another here within
Chris’ group never factors in all the work that Operations needs to do.
there are four types of IT Operations work: business projects, IT Operations projects, changes, and unplanned work. But, we’re only talking about the first type of work, and the unplanned work that get’s created when we do it wrong. We’re only talking about half the work we do in IT Operations.”
“We are way over capacity, given the amount of work in front of us. And we haven’t even counted properly the big audit finding remediation project yet, which Steve says is still top-priority.”
“She said that she would first look at the order and then look at the bill of materials and routings. Based on that, she would look at the loadings of the relevant work centers in the plant and then decide whether accepting the order would jeopardize any existing commitments.
I’m pretty sure we don’t do any sort of analysis of capacity and demand before we accept work. Which means we’re always scrambling, having to take shortcuts, which means more fragile applications in production. Which means more unplanned work and firefighting in the future. So, around and around we go.”
“Well put, Bill. You’ve just described ‘technical debt’ that is not being paid down. It comes from taking shortcuts, which may make sense in the short-term. But like financial debt, the compounding interest costs grow over time. If an organization doesn’t pay down its technical debt, every calorie in the organization can be spent just paying interest, in the form of unplanned work.” “As you know, unplanned work is not free,” he continues. “Quite the opposite. It’s very expensive, because unplanned work comes at the expense of…” He looks around professorially for an answer. Wes finally speaks up, “Planned work?”
Creating and prioritizing work inside a department is hard. Managing work among departments must be at least ten times more difficult.
“What that graph says is that everyone needs idle time, or slack time. If no one has slack time, WIP gets stuck in the system. Or more specifically, stuck in queues, just waiting.”
work breakdown structure, or WBS.
“You know, if we can standardize all our recurring deployment work, we’ll finally be able to enforce uniformity of our production configurations.
Patty says, “You know, deployments are like final assembly in a manufacturing plant. Every flow of work goes through it, and you can’t ship the product without it. Suddenly, I know exactly what the kanban should look like.”
Patty proposes a new role, a combination of a project manager and expediter. Instead of day-by-day oversight, they would provide minute-by-minute control. She says, “We need fast and effective handoffs of any completed work to the next work center. If necessary, this person will wait at the work center until the work is completed and carry to the next work center. We’ll never let critical work get lost in a pile of tickets again.”
“As part of the First Way, you must gain a true understanding of the business system that IT operates in. W. Edwards Deming called this ‘appreciation for the system.’ When it comes to IT, you face two difficulties: On the one hand, in Dick’s second slide, you now see that there are organizational commitments that IT is responsible for helping uphold and protect that no one has verbalized precisely yet. On the other hand, John has discovered that some IT controls he holds near and dear aren’t needed, because other parts of the organization are adequately mitigating those risks. “This is all about scoping what really matters inside of IT. And like when Mr. Sphere told everyone in Flatland, you must leave the realm of IT to discover where the business relies on IT to achieve its goals.” I hear him continue, “Your mission is twofold: You must find where you’ve under-scoped IT—where certain portions of the processes and technology you manage actively jeopardizes the achievement of business goals—as codified by Dick’s measurements. And secondly, John must find where he’s over-scoped IT, such as all those SOX-404 IT controls that weren’t necessary to detect material errors in the financial statements. “You may think that we’re mixing apples and oranges, but I assure you that we are not,” he continues. “Some of the wisest auditors say that there are only three internal control objectives: to gain assurance for reliability of financial reporting, compliance with laws and regulations, and efficiency and effectiveness of operations. That’s it. What you and John are talking about are just different slides of what is called the ‘COSO Cube.’ ”
“You must understand the value chains required to achieve each of Dick’s goals, including the ones that aren’t so visible, like those in IT. For instance, if you were a cross-country freight shipping company that delivers packages using a fleet of one hundred trucks, one of your corporate goals would be customer satisfaction and on-time delivery.” I hear him continue, “Everybody knows that one factor jeopardizing on-time delivery is vehicle breakdowns. A key causal factor for vehicle breakdowns is failure to change the oil. So, to mitigate that risk, you’d create an SLA for vehicle operations to change the oil every five thousand miles.” Obviously enjoying himself, he keeps explaining, “Our organizational key performance indicator (KPI) is on-time delivery. So to achieve it, you would create a new forward-looking KPI of, say, the percentage of vehicles that have had their required oil changes performed. “After all, if only fifty percent of our vehicles are complying with the required maintenance policies, it’s a good bet that in the near future, our on-time delivery KPIs are going to take a dive, when trucks start getting stranded on the side of the road, along with all the packages they’re carrying. “People think that just because IT doesn’t use motor oil and carry physical packages that it doesn’t need preventive maintenance,” Erik says, chuckling to himself. “That somehow, because the work and the cargo that IT carries are invisible, you just need to sprinkle more magic dust on the computers to get them running again.
The need to continually reduce cycle times is part of the First Way. The need for amplification of feedback loops, ideally from the customer, is part of the Second Way.
Then I draw the following table: Pointing at the whiteboard, I say, “The first column names the business capabilities and processes needed to achieve Dick’s desired outcomes; the second column lists the IT systems that those business processes rely upon; the third column lists what can go wrong with either the IT systems or data; and in the fourth column, we’ll write down the countermeasures to prevent those bad things from happening, or at a minimum, detect and respond.”
“Seems pretty obvious to me. We need to come with the controls to mitigate the risks in your third column. We then show this table to Ron and Maggie, and make sure they believe that our countermeasures help them achieve their objectives.
They integrated ‘compliance with vehicle maintenance procedures’ as a leading indicator for ‘on-time delivery’ and ‘customer retention.’ We need to do the same.”
So, Dick, explain why on that little measurement spreadsheet of yours, you list four levels of management for each of your measurements but nowhere are there any IT managers listed. Why?”
they’re not IT risks. They’re business risks.”
We need to make our releases smaller and shorter and deliver cash back faster, so we can beat the internal hurdle rate.
We’re curbing the handoffs of defects to downstream work centers, managing the flow of work, setting the tempo by our constraints, and, based on our results from audit and from Dick, we’re understanding better than we ever have what is important versus what is not.
great team performs best when they practice. Practice creates habits, and habits create mastery of any process or skill. Whether it’s calisthenics, sports training, playing a musical instrument, or in my experience, the endless drilling we did in the Marines. Repetition, especially for things that require teamwork, creates trust and transparency.
There should be absolutely no way that the Dev and QA environments don’t match the production environment.”
me, the answer to your problem is obvious. The First Way is all about controlling the flow of work from Development to IT Operations. You’ve improved flow by freezing and throttling the project releases, but your batch sizes are still way too large. The deployment failure on Friday is proof. You also have way too much WIP still trapped inside the plant, and the worst kind, too. Your deployments are causing unplanned recovery work downstream.” He continues, “Now you must prove that you can master the Second Way, creating constant feedback loops from IT Operations back into Development, designing quality into the product at the earliest stages. To do that, you can’t have nine-month-long releases. You need much faster feedback. “You’ll never hit the target you’re aiming at if you can fire the cannon only once every nine months. Stop thinking about Civil War era cannons. Think antiaircraft guns.”
“In any system of work, the theoretical ideal is single-piece flow, which maximizes throughput and minimizes variance. You get there by continually reducing batch sizes. “You’re doing the exact opposite by lengthening the Phoenix release intervals and increasing the number of features in each release. You’ve even lost the ability to control variance from one release to the next.”
“The flow of work should ideally go in one direction only: forward. When I see work going backward, I think ‘waste.’ It might be because of defects, lack of specification, or rework… Regardless, it’s something we should fix.”
the goal is single-piece flow.”
You must have faster cycle times.
“To do this, you’ll need to put Brent at the very front of the line, just like Herbie in The Goal. Brent needs to be working at the earliest stages of the development process.
any work center is warring with the other work centers, especially if Manufacturing is at war with Engineering, every inch of progress will be a struggle.” Erik turns to me, pointing, “You’ve got to stop thinking like a work center supervisor. You need to think bigger, like a plant manager. Or better yet, think like the person who designed this manufacturing plant and all of the processes it relies upon. They look at the entire flow of work, identify where the constraints are, and use every possible technology and bit of process knowledge they have to ensure work is performed effectively and efficiently. They harness their ‘inner-Allspaw.’
“In manufacturing, we have a measure called takt time, which is the cycle time needed in order to keep up with customer demand. If any operation in the flow of work takes longer than the takt time, you will not be able to keep up with customer demand.”
“As part of the Second Way, you need to create a feedback loop that goes all the way back to the earliest parts of product definition, design, and development,” he says. “Given the conversations you’re having with Dick, you may even be able to go earlier in the process.”
“During the 1950s, they had a hood stamping process that had a change-over time of almost three days. It required moving huge, heavy dies that weighed many tons. Like us, the setup times were so long that they needed to use large batch sizes, which prevented them from using one stamping machine to manufacture multiple different car models simultaneously. You can’t make one hood for a Prius and then one hood for a Camry if it takes you three days to do the changeovers, right? “What did they do?” he asks rhetorically. “They closely observed all the steps required to do the changeover, and then put in a series of preparations and improvements that brought the changeover time down to under ten minutes. And that, of course, is where the legendary ‘single-minute exchange of die’ term comes from. “We studied all the works of Ohno, Spear, and Rother. We knew that we had to decrease our batch size, but we weren’t dealing with hood stamping dies. We were dealing with painting and curing,” he continues. “After weeks of brainstorming, investigation, and experimentation with Engineering, we had a crazy idea: Maybe we could do the painting and curing in a single machine. We cobbled together an oven that also applied the paint powder onto the parts, which were pulled through on a chain and gear that we took from a bicycle. “We combined four work centers into one, eliminating over thirty manual, error-prone steps, completely automating the work cycle, achieving single-piece flow, and eliminating all that setup time. Throughput went through the roof. “The benefits were enormous,” he says with pride. “First, when defects were found, we fixed them immediately and we didn’t have to scrap all the other parts in that batch. Second, WIP was brought down because each work center never overproduced product, only to sit in the queue of the next work center. But the most important benefit was that order lead times were cut from one month to less than a week. We could build and deliver whatever and however many the customer wanted and never had a warehouse full of crap that we’ d need to liquidate at fire-sale prices.
“You’ve got to figure out how to decrease your changeover time and enable faster deployment cycle time.
Allspaw and Hammond ran the IT Operations and Engineering groups at Flickr. Instead of fighting like cats and dogs, they talked about how they were working together to routinely do ten deploys a day! This is in a world when most IT organizations were mostly doing quarterly or annual deployments. Imagine that. He was doing deploys at a rate one thousand times faster than the previous state of the art.
But I learned that the practices that Allspaw and Hammond espoused are the inevitable outcome of applying the Three Ways to the IT value stream. It totally changed how we managed IT and it saved our company.
“Allspaw taught us that Dev and Ops working together, along with QA and the business, are a super-tribe that can achieve amazing things. They also knew that until code is in production, no value is actually being generated, because it’s merely WIP stuck in the system. He kept reducing the batch size, enabling fast feature flow. In part, he did this by ensuring environments were always available when they were needed. He automated the build and deployment process, recognizing that infrastructure could be treated as code, just like the application that Development ships. That enabled him to create a one-step environment creation and deploy procedure, just like we figured out a way to do one-step painting and curing.
Continuous Delivery. Eric Ries then showed us how this capability can help the business learn and win in his Lean Startup work.”
“you need to create what Humble and Farley called a deployment pipeline. That’s your entire value stream from code check-in to production. That’s not an art. That’s production. You need to get everything in version control. Everything. Not just the code, but everything required to build the environment. Then you need to automate the entire environment creation process. You need a deployment pipeline where you can create test and production environments, and then deploy code into them, entirely on-demand. That’s how you reduce your setup times and eliminate errors, so you can finally match whatever rate of change Development sets the tempo at.”
Get humans out of the deployment business.
Business agility is not just about raw speed. It’s about how good you are at detecting and responding to changes in the market and being able to take larger and more calculated risks. It’s about continual experimentation,
Features are always a gamble. If you’re lucky, ten percent will get the desired benefits. So the faster you can get those features to market and test them, the better off you’ll be. Incidentally, you also pay back the business faster for the use of capital, which means the business starts making money faster, too.
So, get to work with Chris to figure out how at every stage of the agile development process, you not only have shippable code, but a working environment it can deploy into!”
Our sprint intervals are three weeks long. We don’t have anything to deploy ten times a day!”
“Interesting. I would normally call those types of fixes a patch or a minor release. But you’re right—those are deployments, too.
starting at ‘code committed,’ and keep going until the handoff to our group.” He nods and walks to the whiteboard and starts drawing boxes, discussing the steps as he goes. Over the next ten minutes, he proves that there are likely over one hundred steps, including the automated tests run in the Dev environment, creating a QA environment that matches Dev, deploying code into it, running all the tests, deploying and migrating into a fresh staging environment that matches QA, load testing, and finally the baton being passed to IT Operations.
Brent gets up and starts drawing boxes to indicate the packaging of the code for deployment; preparing new server instances; loading and configuring the operating system, databases, and applications; making all the changes to the networks, firewalls, and load balancers; and then testing to make sure the deployment completed successfully.
Each of these steps is like a work center, each with different machines, men, methods, and measures. IT work is probably much more complex than manufacturing work. Not only is the work invisible, making it more difficult to track, but there are far more things that could go wrong.
Countless configurations need to be set correctly, systems need enough memory, all the files need to be put in the right place, and all code and the entire environment need to be operating correctly.
For each of the boxes, she asks how long each of these operations typically takes then jots the number on top of the box. Next, she asks whether this step is typically where work has to wait then draws a triangle before the box, indicating work in process.
Suddenly, I understand what Erik meant when he talked about the “deployment pipeline.” Even though you can’t see our work like in a manufacturing plant, it’s still a value stream.
On a separate whiteboard, she writes down two bullet points: “environments” and “deployment.” Pointing to what she just wrote, she says, “With the current process, two issues keep coming up: At every stage of the deployment process, environments are never available when we need them, and even when they are, there’s considerable rework required to get them all synchronized with one another.
“The other obvious source of rework and long setup time is in the code packaging process, where IT Operations takes what Development checks into version control and then generates the deployment packages. Although Chris and his team do their best to document the code and configurations, something always falls through the cracks, which are only exposed when the code fails to run in the environment after deployment.
build a deployment run book, to capture all the lessons learned from our mistakes?”
three boxes labeled “Dev,” “QA,” and “Production.” And then underneath them, he draws another box labeled “Build Procedure” with arrows into each of the boxes above. “That’s actually pretty brilliant, Bill,” he says. “If we had a common build procedure, and everyone used these tools to create their environments, the developers would actually be writing code in an environment that at least resembles the Production environment. That alone would be a huge improvement.”
“Brent, if it’s okay with you and everyone else, I’d like to invite you to our team sprints, so that we can get environment creation integrated into the development process as early as possible. Right now, we focus mostly on having deployable code at the end of the project. I propose we change that requirement. At each three-week sprint interval, we not only need to have deployable code but also the exact environment that the code deploys into, and have that checked into version control, too.”
“On the manufacturing floor, whenever we see work go backward, that’s rework. When that happens, you can bet that the amount of documentation and information flow is going to be pretty poor, which means nothing is reproducible and that it’s going to get worse over time as we try to go faster. They call this ‘non-value-add’ activity or ‘waste.’ ”
“If I could wave this magic wand, I would change this step. Instead of getting source code or compiled code from Dev through source control, I want packaged code that’s ready to be deployed.”
She would be responsible for the Dev handoff. When code is labeled ‘ready to test,’ we would then generate and commit the packaged code, which would trigger an automated deployment into the QA environment. And later, maybe even the Production environment, too.”
the developers and Brent decided to create a completely new database, using open source tools, with data copied from not only Phoenix but also the order entry and inventory management systems. By doing this, we could develop, test, and even run in operations without impacting Phoenix or other business critical applications. And by decoupling ourselves from the other projects, we could make all the changes we needed to without putting other projects at risk. At
the meantime, Brent worked with William’s team to create the build procedures and automated mechanisms that could simultaneously create the Dev, QA, and Production environments. We were all astonished that within the three-week sprint, perhaps for the first time in memory, all the developers were using exactly the same operating system, library versions, databases, database settings, and so forth.
“For Phoenix, it takes us three or four weeks for new developers to get builds running on their machine, because we’ve never assembled the complete list of the gazillion things you need installed in order for it to compile and run. But now all we have to do is check out the virtual machine that Brent and team built, and they’re all ready to go.”
Similarly, we were all amazed that we had a QA environment available that matched Dev so early in the project. That, too, was unprecedented. We needed to make a bunch of adjustments to reflect that the Dev systems had considerably less memory and storage than QA, and QA had less than those in Production. But the vast majority of the environments were identical and could be modified and spun up in minutes.
Because of our rapid progress, we decided to shrink the sprint interval to two weeks. By doing this, we could reduce our planning horizon, to make and execute decisions more frequently, as opposed to sticking to a plan made almost a month ago.
We need to create a culture that reinforces the value of taking risks and learning from failure and the need for repetition and practice to create mastery.
It’s Product Management, Development, IT Operations, and even Information Security all working together and supporting one another.
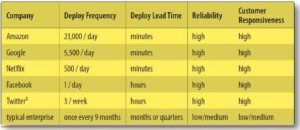
In the 2012 Puppet Labs “State of DevOps Report”,3 we were able to benchmark 4,039 IT organizations, with the goal of better understanding the health and habits of organizations at all stages of DevOps adoption.
We have a high-trust, collaborative culture, where everyone is responsible for the quality of their work. Instead of approval and compliance processes, the hallmark of a low-trust, command-and-control management culture, we rely on peer review to ensure that everyone has confidence in the quality of their code. Furthermore, there is a hypothesis-driven culture, requiring everyone to be a scientist, taking no assumptions for granted and doing nothing without measuring. Why? Because we know that our time is valuable. We don’t spend years building features that our customers don’t actually want, deploying code that doesn’t work, or fixing something that isn’t actually the problem. All
Paradoxically, performing code deployments becomes boring and routine. Instead of being performed only at night or on weekends, full of stress and chaos, we are deploying code throughout the business day, without most people even noticing. And because code deployments happen in the middle of the afternoon instead of on weekends, for the first time in decades, IT Operations is working during normal business hours, like everyone else. Just how did code deployment become routine? Because developers are constantly getting fast feedback on their work: when they write code, automated unit, acceptance, and integration tests are constantly being run in production-like environments, giving us continual assurance that the code and environment will operate as designed, and that we are always in a deployable state. And when the code is deployed, pervasive production metrics demonstrate to everyone that it is working, and the customer is getting value. Even our highest-stakes feature releases have become routine. How? Because at product launch time, the code delivering the new functionality is already in production. Months prior to the launch, Development has been deploying code into production, invisible to the customer, but enabling the feature to be run and tested by internal staff. At the culminating moment when the feature goes live, no new code is pushed into production. Instead, we merely change a feature toggle or configuration setting. The new feature is slowly made visible to small segments of customers, automatically rolled back if something goes wrong. Only when we have confidence that the feature is working as designed do we expose it to the next segment of customers, rolled out in a manner that is controlled, predictable, reversible, and low stress. We repeat until everyone is using the feature. By doing this, we not only significantly reduce deployment risk, but we increase the likelihood of achieving the desired business outcomes, as well. Because we can do deployments quickly, we can do experiments in production, testing our business hypotheses for every feature we build. We can iteratively test and refine our features in production, using feedback from our customers for months, and maybe even years. It is no wonder that we are out-experimenting our competition and winning in the marketplace. All this is made possible by DevOps, a new way that Development, Test, and IT Operations work together, along with everyone else in the IT value stream.
DevOps shows how we optimize the IT value stream, converting business needs into capabilities and services that provide value for our customers. During the 1980s, there was a very well-known core, chronic conflict in manufacturing: Protect sales commitments Control manufacturing costs In order to protect sales commitments, the product sales force wanted lots of inventory on hand, so that customers could always get products when they wanted it. However, in order to reduce costs, plant managers wanted to reduce inventory levels and work in process (WIP).
They were able to break the conflict by adopting Lean principles, such as reducing batch sizes, reducing work in process, and shortening and amplifying feedback loops. This resulted in dramatic increases in plant productivity, product quality, and cu
“10+ Deploys Per Day: Dev and Ops Cooperation at Flickr” presentation, given by John Allspaw and Paul Hammond.9
we refer to “DevOps” as the outcome of applying Lean principles to the IT value stream.
DevOps has benefited tremendously from the work the Agile Community has done, showing how small teams operating with high trust combined with small batch sizes and smaller, more frequent software releases can dramatically increase productivity of Development organizations. In fact, many of the key moments in the DevOps history happened at Agile conferences, in addition to the incredibly vibrant DevOpsDays events happening around the world since the first one was held in 2009.
DevOps also benefits from an astounding convergence of philosophical management movements, such as Lean Startup, Innovation Culture, Toyota Kata, Rugged Computing, and the Velocity community. All of these mutually reinforce each other, creating the conditions of a powerful coalition of forces that can accelerate DevOps adoption.
The Three Ways Explained In The Phoenix Project, we describe the underpinning principles that all the DevOps patterns can be derived from as “The Three Ways.” It is intended to describe the values and philosophies that guide DevOps processes and practices.
The First Way is about the left-to-right flow of work from Development to IT Operations to the customer. In order to maximize flow, we need small batch sizes and intervals of work, never passing defects to downstream work centers, and to constantly optimize for the global goals (as opposed to local goals such as Dev feature completion rates, Test find/fix ratios, or Ops availability measures).
The necessary practices include continuous build, integration, and deployment, creating environments on demand, limiting work in process, and building safe systems and organizations that are safe to change.
The Second Way is about the constant flow of fast feedback from right-to-left at all stages of the value stream, amplifying it to ensure that we can prevent problems from happening again or enable faster detection and recovery. By doing this, we create quality at the source, creating or embedding knowledge where we need it.
The necessary practices include “stopping the production line” when our builds and tests fail in the deployment pipeline; constantly elevating the improvement of daily work over daily work; creating fast automated test suites to ensure that code is always in a potentially deployable state; creating shared goals and shared pain between Development and IT Operations; and creating pervasive production telemetry so that everyone can see whether code and environments are operating as designed and that customer goals are being met.
The Third Way is about creating a culture that fosters two things: continual experimentation, which requires taking risks and learning from success and failure, and understanding that repetition and practice is the prerequisite to mastery.
Experimentation and risk taking are what enable us to relentlessly improve our system of work, which often requires us to do things very differently than how we’ve done it for decades. And when things go wrong, our constant repetition and daily practice is what allows us to have the skills and habits that enable us to retreat back to a place of safety and resume normal operations.
The necessary practices include creating a culture of innovation and risk taking (as opposed to fear or mindless order taking) and high trust (as opposed to low trust, command-and-control), allocating at least twenty percent of Development and IT Operations cycles towards nonfunctional requirements, and constant reinforcement that improvements are encouraged and celebrated.
DevOps is the logical continuation of the Agile journey that was started in 2001, because we now know that the real definition of “done” is not when Development is done coding. Instead, code is only “done” when it has been when it has been fully tested and is operating in production as designed.
ITIL and ITSM remain the best codifications of the processes that underpin IT Operations, and actually describe many of the capabilities needed in order for IT Operations to support a DevOps-style work stream.
In order to accommodate the faster lead times and higher deployment frequencies associated with DevOps, many areas of the ITIL processes require automation, specifically around the change, configuration, and release processes.
In order to support fast lead times and enable developer productivity, DevOps does require many IT Operations tasks to become self-service.
DevOps principles are universal, and they are largely independent of the underlying technology being used. Some of the DevOps patterns have specific technology requirements (e.g., able to support automated testing, able to expose configurations that can be checked into version control), which are often more prevalent in open source software.
DevOps also requires shared goals and shared pain throughout the IT value stream.
Paychex,
The Four Types of Work
Because work can be assigned to people in more ways than ever (e.g., via e-mails, phone calls, hallway conversations, text messages, ticketing systems, meetings, and so forth), we want to make visible our existing commitments. Erik convinces Bill that there are four types of work that IT does:
Business projects
These are business initiatives, of which most Development projects encompass. These typically reside in the Project Management Office, which tracks all the official projects in an organization.
Internal IT projects
These include the infrastructure or IT Operations projects that business projects may create, as well as internally generated improvement projects (e.g., create new environment, automate deployment). Often these are not centrally tracked anywhere, instead residing with the budget owners (e.g., database manager, storage manager, distributed systems manager)
This creates a problem when IT Operations is a bottleneck, because there is no easy way to find out how much of capacity is already committed to internal projects.
Changes
These are often generated from the previous two types of work and are typically tracked in a ticketing system (e.g., Remedy for IT Operations, JIRA, or an Agile planning tool for Development). The fact that two systems exist to track work for two different parts of the value stream can create problems, especially when handoffs are required.
Incidentally, in some dedicated teams that own both the feature development and service delivery responsibilities, all work lives in the same system. This has some advantages, because operational incidents will show up in the backlog and “in work,” alongside feature defects and new feature functionality.
Unplanned work or recovery work
These include operational incidents and problems, often caused by the previous types of work and always come at the expense of other planned work commitments.
Why Do We Need To Visualize IT Work And Control WIP?
My favorite (and only) graph in The Phoenix Project shows wait time as a function of how busy a resource at a work center is. Erik used this to show why Brent’s simple thirty-minute changes were taking weeks to get completed. The reason, of course, is that as the bottleneck of all work, Brent is constantly at or above one hundred percent utilization, and therefore, anytime we required work from him, the work just languished in queue, never worked on without expediting or escalating.
Here’s what the graph shows: on the x-axis is the percent busy for a given resource at a work center, and on the y-axis is the approximate wait time (or maybe more precisely stated, the queue length). What the shape of the line shows is that, as resource utilization goes past eighty percent, wait time goes through the roof.
“The wait time is the ‘percentage of time busy’ divided by the ‘percentage of time idle.’ In other words, if a resource is fifty percent busy, then it’s fifty percent idle. The wait time is fifty percent divided by fifty percent, so one unit of time. Let’s call it one hour.
So, on average, our task would wait in the queue for one hour before it gets worked.
“On the other hand, if a resource is ninety percent busy, the wait time is ‘ninety percent divided by ten percent’, or nine hours. In other words, our task would wait in queue nine times longer than if the resource were fifty percent idle.”
I conclude, “So, for the Phoenix task, assuming we have seven handoffs, and that each of and that each of those resources is busy ninety percent of the time, the tasks would spend in queue a total of nine hours times the seven steps…” “What? Sixty-three hours, just in queue time?”
In other words, the total “% of value added time” (sometimes known as “touch time”) was only 0.16% of the total lead time (thirty minutes divided by sixty-three hours). That means for 99.8% of our total lead time, the work was simply sitting in queue, waiting to be worked on (e.g., in a ticketing system, in an e-mail).
In the graph, I believe “wait time” is actually a proxy for “queue length.” In other words, because it’s not time elapsed, it has no time units (i.e., it’s neither minutes, hours, days).
The Goal: A Process of Ongoing Improvement Dr. Eliyahu Goldratt wrote his seminal book, The Goal: A Process of Ongoing Improvement, in 1984. It’s a Socratic novel about Alex Rogo, a plant manager who must fix his cost and due date issues in ninety days, or his plant will be shut down.
The Goal, Dr. Goldratt starts to describe the steps in the Theory of Constraints (TOC) methodology. Briefly, the five original TOC steps are:
- Identify the constraint
- Exploit the constraint
- Subordinate all other activities to the constraint
- Elevate the constraint to new levels
- Find the next constraint
By far, the very best overview of the entire TOC, the Thinking Processes, and Dr. Goldratt’s body of knowledge is an audiobook called Beyond The Goal. It includes all of his recorded lectures from 2005 and is a breathtaking tour of Dr. Goldratt’s life journey, describing his contributions, tools, and case studies.
Dr. James Holt’s EM 526 Constraints Management and EM 530 Applications of Constraints Management courses, offered online through Washington State University.
The Five Dysfunctions of A Team: A Leadership Fable
Patrick Lencioni’s methodology described in The Five Dysfunctions of a Team: A Leadership Fable. He posits that one of the core contributors to a team’s inability to achieve goals is due to lack of trust. In his model, the five dysfunctions are described as: Absence of trust—unwilling to be vulnerable within the group Fear of conflict—seeking artificial harmony over constructive passionate debate Lack of commitment—feigning buy-in for group decisions creates ambiguity throughout the organization Avoidance of accountability—ducking the responsibility to call peers on counterproductive behavior, which sets low standards Inattention to results—focusing on personal success, status, and ego before team success
When I think about the long, bitter intertribal warfare that has existed between Development and IT Operations, as well as between IT and “the business,” I suspect that we will very much need the lessons of Mr. Lencioni to achieve the DevOps ideal.
From my professional experience, the cost and true consequence of not being able to have candid discussions about problems that everyone knows about, but is unwilling to confront, is incredibly high.
Toyota Kata: Managing People for Improvement, Adaptiveness and Superior Results by Shingo Prize winner Mike Rother.
his three-day course, “Improvement Kata and Coaching Kata,” offered through University of Michigan. It includes two days of fieldwork in a real manufacturing plant.
Mr. Rother’s lessons have been codified in the book Toyota Kata, which frames the thought process and culture that must exist to enable the Lean PDCA cycle (Plan, Do, Check, Act). I believe that this is one of the most extraordinary contributions to the world of process improvement.

The most obvious manifestation of the Toyota Kata is the two-week improvement cycle, in which every work center supervisor must improve something (anything!) every two weeks. To quote Mr. Rother, “The practice of kata is the act of practicing a pattern so it becomes second nature. In its day-to-day management, Toyota teaches a way of working—a kata—that has helped make it so successful over the last six decades.”
In my mind, Patty’s ITIL/ITSM crusade is very much like the Lean practitioners that Mr. Rother describes who were never able to replicate the performance of Toyota. Why? They’d do a Lean Kaizen event once per year, but then get marginalized from daily operations the remainder of the year.
For us to get the performance gains promised by ITIL/ITSM, Lean, or whatever, we must create a culture of relentless improvement described by Mr. Rother.
Kata impacts your organization by
- providing a systematic, scientific routine that can be applied to any problem or challenge,
- commonizing how the members of an organization develop solutions,
- migrating managers toward a role of coach and mentor, by having them practice coaching cycles, and
- framing PDCA in a way that has people taking small steps every day.
Mr. Rother asserts that if a system is not improving, the result is not a steady state. Instead, because of entropy, organizational performance declines.
Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation Erik’s First Way underscores the importance of the performance of the entire system, as opposed to the performance of a specific silo of work or department—this as can be as large a division (e.g., Development or IT Operations) or as small as an individual contributor (e.g., a developer, a system administrator).
In the IT value stream, this is all about the left-to-right flow of work from Development into IT Operations. Probably the best embodiment of this work is Jez Humble and David Farley’s seminal book Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation.
They codify many of the techniques required to replicate the famous 2009 Velocity Conference presentation, “10+ Deploys Per Day: Dev and Ops Cooperation at Flickr,” given by John Allspaw and Paul Hammond, as well as the Agile system administration movement.23
Continuous delivery is the extension of continuous integration, which are the Development practices that include continuous builds, continuous testing, daily integration of branches back into trunk, testing in a clone of the production environment, etc. Continuous delivery techniques extend these processes all the way into the production environment.
Continuous deployment is a prerequisite for the high deploy rates characterized by DevOps, and is therefore a needed skill set for the modern DevOps practitioner. It will also be the salvation for a generation of ITSM practitioners. Read it.
Michael T. Nygard in his fantastic book, Release It!: Design and Deploy Production-Ready Software.24
This is a book that helps span the Development and IT Operations divide, by showing developers and architects how to build applications that can be deployed and managed and survive in even the most hostile production environments. When you read this book, you’ll see in his patterns and lessons horror stories from your own past.
IT Operations practitioners need to read this book, too, in order to connect the dots of how specific Development decisions lead to bad production outcomes that they’ve experienced in the past. And more importantly, it will enable them to go to architecture or development meetings with concrete suggestions on how to avoid them in the future.
A critical part of this journey was made possible by the ITIL Service Support Book (v2), which no discussion about IT Operations would be complete without.
Two Great Books on Kanbans
I have two favorite books on kanbans that I’d recommend to anyone who is even remotely interested in kanbans.
The first book is Personal Kanban: Mapping Work | Navigating Life by Jim Benson and Tonianne DeMaria Barry. This book is more of a personal productivity book than a book about complex value streams. In fact, I’d call this book the modern version of David Allen’s famous book Getting Things Done: The Art of Stress-Free Productivity.
Where Allen discussed the nature of work, the importance of calendars for keeping commitments, and the theory of filing and contextual TODO lists, Benson and Tonianne discuss the need to visualize all our work and control the amount of WIP. They advocate that everyone should start their own kanban boards with three simple lanes: Ready, Doing, and Done.26
On the other hand, with kanban boards, all my work is visible, and there are WIP limits in place that prevent the number going above a fixed limit. I’ve seen on Jim Benson’s kanban board in his office and his Doing WIP limit is four (i.e., no more than four cards are allowed in the Doing lane).
David J. Anderson’s book Kanban: Successful Evolutionary Change for Your Technology Business; it’s more specific to the use of kanban boards in organizations.
2005 paper called, “From Worst to Best in 9 Months: Implementing a Drum-Buffer-Rope Solution in Microsoft’s IT Department” by David J. Anderson and Dragos Dumitriu.